Running Experiments¶
PyTerrier aims to make it easy to conduct an information retrieval experiment, namely, to run a transformer pipeline over a set of queries, and evaluating the outcome using standard information retrieval evaluation metrics based on known relevant documents (obtained from a set relevance assessments, also known as qrels).
NB: For calculating evaluation metrics, we use ir_measures library, which includes implementations of many standard metrics. By default, to calculate more measures, ir_measures uses our fork of the pytrec_eval library, which itself is a Python wrapper around the widely-used trec_eval evaluation tool.
The main way to achieve this is using pt.Experiment(). If you have an existing results dataframe, you can use
pt.Evaluate().
API¶
- pyterrier.Experiment(retr_systems, topics, qrels, eval_metrics, names=None, perquery=False, dataframe=True, batch_size=None, filter_by_qrels=False, filter_by_topics=True, baseline=None, test='t', correction=None, correction_alpha=0.05, highlight=None, round=None, verbose='auto', validate='warn', save_dir=None, save_mode='warn', save_format='trec', precompute_prefix=False, plan='linear', **kwargs)[source]¶
Allows easy comparison of multiple retrieval transformer pipelines using a common set of topics, and identical evaluation measures computed using the same qrels. In essence, each transformer is applied on the provided set of topics. Then the named evaluation measures are computed for each system.
- Parameters:
retr_systems (
Sequence[Transformer|DataFrame] |Dict[str,Transformer|DataFrame]) – A list of transformers to evaluate. If you already have the results for one (or more) of your systems, a results dataframe can also be used here. Results produced by the transformers must have “qid”, “docno”, “score”, “rank” columns. A dict can also be provided, in which case keys are used as system names and values are the systems/results.topics (
DataFrame) – Either a path to a topics file or a pandas.Dataframe with columns=[‘qid’, ‘query’]qrels (
DataFrame) – Either a path to a qrels file or a pandas.Dataframe with columns=[‘qid’,’docno’, ‘label’]eval_metrics (
Sequence[str|Measure]) – Which evaluation metrics to use. E.g. [‘map’]names (
Sequence[str] |None) – List of names for each retrieval system when presenting the results. Default=None. If None: Obtains the str() representation of each transformer as its name. Ignored whenretr_systemsis a dict.batch_size (
int|None) – If not None, evaluation is conducted in batches of batch_size topics. Default=None, which evaluates all topics at once. Applying a batch_size is useful if you have large numbers of topics, and/or if your pipeline requires large amounts of temporary memory during a run.filter_by_qrels (
bool) – If True, will drop topics from the topics dataframe that have qids not appearing in the qrels dataframe.filter_by_topics (
bool) – If True, will drop topics from the qrels dataframe that have qids not appearing in the topics dataframe.perquery (
bool|Literal['both']) – If True return each metric for each query, if False, will return mean metrics across all queries. If both, will return both averages and perquery results in a tuple. Default=False.save_dir (
str|None) – If set to the name of a directory, the results of each transformer will be saved in TREC-formatted results file, whose filename is based on the systems names (as specified bynameskwarg). If the file exists andsave_modeis set to “reuse”, then the file will be used for evaluation rather than the transformer. Default is None, such that saving and loading from files is disabled. In addition, two CSV summary files are written tosave_diron every call:aggregated.csv(one row per system, one column per measure) andperquery.csv(long-format table with columnsname,qid,measure,value). If either CSV already exists, rows for systems not in the current experiment are preserved, allowing results to accumulate across multiple calls topt.Experimentthat each evaluate different subsets of systems.save_mode (
Literal['reuse','overwrite','error','warn']) – Defines how existing files are used whensave_diris set. If set to “reuse”, then files will be preferred over transformers for evaluation. If set to “overwrite”, existing files will be replaced. If set to “warn” or “error”, the presence of any existing file will cause a warning or error, respectively. Default is “warn”.save_format (
Literal['trec'] |ModuleType|Tuple[Callable[[IO],DataFrame],Callable[[DataFrame,IO],None]]) – How are result being saved. Defaults to ‘trec’, which usespt.io.read_results()andpt.io.write_results()for saving system outputs. If TREC results format is insufficient, setsave_format=pickle. Alternatively, a tuple of read and write function can be specified, for instance,save_format=(pandas.from_csv, pandas.DataFrame.to_csv), or evensave_format=(pandas.from_parquet, pandas.DataFrame.to_parquet).dataframe (
Literal[False] |Literal[True]) – If True return results as a dataframe, else as a dictionary of dictionaries. Default=True.baseline (
int|str|None) – If set to the index of an item of the retr_system list, will calculate the number of queries improved, degraded and the statistical significance (paired t-test p value) for each measure. Whenretr_systemsis a dict, baseline can also be a system name (dict key). Default=None: If None, no additional columns will be added for each measure.test (
str|Callable[[Sequence[float|int|complex],Sequence[float|int|complex]],Tuple[Any,float|int|complex]]) – Which significance testing approach to apply. Defaults to “t”. Alternatives are “wilcoxon” - not typically used for IR experiments. A Callable can also be passed - it should follow the specification of scipy.stats.ttest_rel(), i.e. it expect two arrays of numbers, and return an array or tuple, of which the second value will be placed in the p-value column.correction (
str|None) – Whether any multiple testing correction should be applied. E.g. ‘bonferroni’, ‘holm’, ‘hs’ aka ‘holm-sidak’. Default is None. Additional columns are added denoting whether the null hypothesis can be rejected, and the corrected p value. See statsmodels.stats.multitest.multipletests() for more information about available testing correction.correction_alpha (
float) – What alpha value for multiple testing correction. Default is 0.05.highlight (
str|None) – If highlight=”bold”, highlights in bold the best measure value in each column; if highlight=”color” or “colour”, then the cell with the highest metric value will have a green background.round (
int|Dict[str,int] |None) – How many decimal places to round each measure value to. This can also be a dictionary mapping measure name to number of decimal places. Default is None, which is no rounding.plan (
Literal['linear','tree']) – Whether to execute the experiment using a ‘linear’ or ‘tree’ execution plan. The linear plan executes each system sequentially, but does not allow for reuse of execution results between different systems. The tree plan identifies common prefixes between pipelines, and executes each unique prefix only once, allowing for more faster experiments. Default is ‘linear’.verbose (
Literal['auto',True,False]) – If True, progress is shown as systems (or systems*batches if batch_size is set) are executed. Default is False, except whenplan='tree'in a notebook, in which case a the tree-execution plan is shown by default.validate (
Literal['warn','error','ignore']) – If set to value other than ‘ignore’, each transformer is validated against the topics dataframe, to ensure that it produces the expected output columns.pt.inspect.transformer_outputs()is used to determine the output columns. If ‘warn’, then transformers whose output columns don’t match the columns required by the specified evaluation measures will product warnings; If ‘error’, then an error is produced. If a transformer cannot be inspected, a warning is produced.precompute_prefix (
bool) – Deprecated, use plan=’tree’ instead. If True, will precompute the common prefix of all retrieval systems, and use this to speed up evaluation. Default is False. A tree execution plan is more efficient, as prefixes of different lengths can be reused, and is recommended for experiments with many systems.
- Returns:
A Dataframe/dict with each retrieval system with each metric evaluated, or alternatively a tuple with averages and perquery results.
- pyterrier.Evaluate(res, qrels, metrics=['map', 'ndcg'], perquery=False)[source]¶
Evaluate a single result dataframe with the given qrels. This method may be used as an alternative to
pt.Experiment()for getting only the evaluation measurements given a single set of existing results.The PyTerrier-way is to use
pt.Experiment()to evaluate a set of transformers, but this method is useful if you have a set of results already, and want to evaluate them without having to create a transformer pipeline.- Parameters:
res (
DataFrame) – Either a dataframe with columns=[‘qid’, ‘docno’, ‘score’] or a dict {qid:{docno:score,},}qrels (
DataFrame) – Either a dataframe with columns=[‘qid’,’docno’, ‘label’] or a dict {qid:{docno:label,},}metrics (
Sequence[str|Measure]) – A list of strings specifying which evaluation metrics to use. Default=[‘map’, ‘ndcg’]perquery (
bool) – If true return each metric for each query, else return mean metrics. Default=False
- Return type:
Dict
Examples¶
Average Effectiveness¶
Getting average effectiveness over a set of topics:
dataset = pt.get_dataset("vaswani")
# vaswani dataset provides an index, topics and qrels
# lets generate two BRs to compare
tfidf = pt.terrier.Retriever(dataset.get_index(), wmodel="TF_IDF")
bm25 = pt.terrier.Retriever(dataset.get_index(), wmodel="BM25")
pt.Experiment(
[tfidf, bm25],
dataset.get_topics(),
dataset.get_qrels(),
eval_metrics=["map", "recip_rank"]
)
The returned dataframe is as follows:
name |
map |
recip_rank |
|
|---|---|---|---|
0 |
TerrierRetr(TF_IDF) |
0.290905 |
0.699168 |
1 |
TerrierRetr(BM25) |
0.296517 |
0.725665 |
Each row represents one system. We can manually set the names of the systems, using the names= kwarg, as follows:
pt.Experiment(
[tfidf, bm25],
dataset.get_topics(),
dataset.get_qrels(),
eval_metrics=["map", "recip_rank"],
names=["TF_IDF", "BM25"]
)
This produces dataframes that are more easily interpretable.
name |
map |
recip_rank |
|
|---|---|---|---|
0 |
TF_IDF |
0.290905 |
0.699168 |
1 |
BM25 |
0.296517 |
0.725665 |
You can also provide systems as a dictionary, where keys are used as system names and can be referenced directly as the baseline:
pt.Experiment(
{"TF_IDF": tfidf, "BM25": bm25},
dataset.get_topics(),
dataset.get_qrels(),
eval_metrics=["map", "recip_rank"],
baseline="TF_IDF",
)
We can also reduce the number of decimal places reported using the round= kwarg, as follows:
pt.Experiment(
[tfidf, bm25],
dataset.get_topics(),
dataset.get_qrels(),
eval_metrics=["map", "recip_rank"],
round={"map" : 4, "recip_rank" : 3},
names=["TF_IDF", "BM25"]
)
The result is as follows:
name |
map |
recip_rank |
|
|---|---|---|---|
0 |
TF_IDF |
0.2909 |
0.699 |
1 |
BM25 |
0.2965 |
0.726 |
Passing an integer value to round= (e.g. round=3) applies rounding to all evaluation measures.
Significance Testing¶
We can perform significance testing by specifying the index of which transformer we consider to be our baseline, e.g. baseline=0:
pt.Experiment(
[tfidf, bm25],
dataset.get_topics(),
dataset.get_qrels(),
eval_metrics=["map", "recip_rank"],
names=["TF_IDF", "BM25"],
baseline=0
)
If the systems are provided as a dictionary, the keys are used as system names and the baseline can be specified by key:
pt.Experiment(
{"TF_IDF": tfidf, "BM25": bm25},
dataset.get_topics(),
dataset.get_qrels(),
eval_metrics=["map", "recip_rank"],
baseline="TF_IDF",
)
In this case, additional columns are returned for each measure, indicating the number of queries improved compared to the baseline, the number of queries degraded, as well as the paired t-test p-value in the difference between each row and the baseline row. NB: For the baseline, these values are NaN (not applicable).
name |
map |
recip_rank |
map + |
map - |
map p-value |
recip_rank + |
recip_rank - |
recip_rank p-value |
|
|---|---|---|---|---|---|---|---|---|---|
0 |
TF_IDF |
0.290905 |
0.699168 |
nan |
nan |
nan |
nan |
nan |
nan |
1 |
BM25 |
0.296517 |
0.725665 |
46 |
45 |
0.237317 |
16 |
3 |
0.0258549 |
For this test collection, between the TF_IDF and BM25 weighting models, there is no significant difference observed in terms of MAP, but there is a significant different in terms of mean reciprocal rank (p<0.05). Indeed, while BM25 improves average precision for 46 queries over TF_IDF, it degrades it for 45; on the other hand, the rank of the first relevant document is improved for 16 queries by BM25 over TD_IDF.
Further more, modern experimental convention suggests that it is important to correct for multiple testing in the comparative evaluation of many IR systems. Experiments provides supported for the multiple testing correction methods supported by the statsmodels package, such as Bonferroni:
pt.Experiment(
[tfidf, bm25],
dataset.get_topics(),
dataset.get_qrels(),
eval_metrics=["map"],
names=["TF_IDF", "BM25"],
baseline=0,
correction='bonferroni'
)
This adds two further columns for each measure, denoting if the null hypothesis can be rejected (e.g. “map reject”), as well as the corrected p value (“map p-value corrected”), as shown below:
name |
map |
map + |
map - |
map p-value |
map reject |
map p-value corrected |
|
|---|---|---|---|---|---|---|---|
0 |
TF_IDF |
0.290905 |
nan |
nan |
nan |
False |
nan |
1 |
BM25 |
0.296517 |
46 |
45 |
0.237317 |
False |
0.237317 |
The table below summarises the multiple testing correction methods supported:
Aliases |
Correction Method |
|
|---|---|---|
0 |
[‘b’, ‘bonf’, ‘bonferroni’] |
Bonferroni |
1 |
[‘s’, ‘sidak’] |
Sidak |
2 |
[‘h’, ‘holm’] |
Holm |
3 |
[‘hs’, ‘holm-sidak’] |
Holm-Sidak |
4 |
[‘sh’, ‘simes-hochberg’] |
Simes-Hochberg |
5 |
[‘ho’, ‘hommel’] |
Hommel |
6 |
[‘fdr_bh’, ‘fdr_i’, ‘fdr_p’, ‘fdri’, ‘fdrp’] |
FDR Benjamini-Hochberg |
7 |
[‘fdr_by’, ‘fdr_n’, ‘fdr_c’, ‘fdrn’, ‘fdrcorr’] |
FDR Benjamini-Yekutieli |
8 |
[‘fdr_tsbh’, ‘fdr_2sbh’] |
FDR 2-stage Benjamini-Hochberg |
9 |
[‘fdr_tsbky’, ‘fdr_2sbky’, ‘fdr_twostage’] |
FDR 2-stage Benjamini-Krieger-Yekutieli |
10 |
[‘fdr_gbs’] |
FDR adaptive Gavrilov-Benjamini-Sarkar |
Any value in the Aliases column can be passed to Experiment’s correction= kwarg.
Per-query Effectiveness¶
Finally, if necessary, we can request per-query performances using the perquery=True kwarg:
pt.Experiment(
[tfidf, bm25],
dataset.get_topics(),
dataset.get_qrels(),
eval_metrics=["map", "recip_rank"],
names=["TF_IDF", "BM25"],
perquery=True
)
This provides a dataframe where each row is the performance of a given system for a give query on a particular evaluation measure.
name |
qid |
measure |
value |
|
|---|---|---|---|---|
186 |
BM25 |
1 |
map |
0.26794 |
187 |
BM25 |
1 |
recip_rank |
1 |
204 |
BM25 |
10 |
map |
0.115631 |
205 |
BM25 |
10 |
recip_rank |
0.5 |
206 |
BM25 |
11 |
map |
0.0776046 |
NB: For brevity, we only show the top 5 rows of the returned table.
Saving and Reusing Results¶
For some research tasks, it is considered good practice to save your results files when conducting experiments. This allows several advantages:
It permits additional evaluation (e.g. more measures, more signifiance tests) without re-applying potentially slow transformer pipelines.
It allows transformer results to be made available for other experiments, perhaps as a virtual data appendix in a paper.
Saving can be enabled by adding the save_dir as a kwarg to pt.Experiment:
pt.Experiment(
[tfidf, bm25],
dataset.get_topics(),
dataset.get_qrels(),
eval_metrics=["map", "recip_rank"],
names=["TF_IDF", "BM25"],
save_dir="./",
)
This will save two files, namely, TF_IDF.res.gz and BM25.res.gz to the current directory. If these files already exist, they will be “reused”, i.e. loaded and evaluated in preference to application of the tfidf and/or bm25 transformers. If experiments are being conducted on multiple different topic sets, care should be taken to ensure that previous results for a different topic set are not reused for evaluation.
If a transformer has been updated, outdated results files can be mistakenly used. To prevent this, set the save_mode
kwarg to "overwrite":
pt.Experiment(
[tfidf, bm25],
dataset.get_topics(),
dataset.get_qrels(),
eval_metrics=["map", "recip_rank"],
names=["TF_IDF", "BM25"],
save_dir="./",
save_mode="overwrite"
)
Saving Evaluation Results as CSVs¶
Whenever save_dir is set, pt.Experiment also writes two CSV summary files to that directory:
aggregated.csv— one row per system with anamecolumn followed by one column per evaluation measure (mirrors the defaultpt.Experimentreturn value).
perquery.csv— a long-format table with columnsname,qid,measure, andvalue, giving per-query metric values for every system.
These files are always written regardless of the value of the perquery kwarg.
If either CSV file already exists (e.g. from a previous call that evaluated TF_IDF and BM25), rows for systems that are not part of the current experiment are loaded from the existing file and merged into the new output. This means that results accumulate across separate experiment calls made to the same save_dir, so no previously-evaluated system’s data is lost when a subsequent experiment evaluates only a subset of systems:
# First run: evaluates TF_IDF and BM25; writes TF_IDF.res.gz, BM25.res.gz, aggregated.csv, perquery.csv
pt.Experiment(
[tfidf, bm25],
dataset.get_topics(),
dataset.get_qrels(),
eval_metrics=["map"],
names=["TF_IDF", "BM25"],
save_dir="./runs",
)
# Second run: evaluates PL2 only; TF_IDF and BM25 rows are preserved in the CSV files
pt.Experiment(
[pl2],
dataset.get_topics(),
dataset.get_qrels(),
eval_metrics=["map"],
names=["PL2"],
save_dir="./runs",
)
# ./runs/aggregated.csv now contains rows for TF_IDF, BM25, and PL2
# ./runs/perquery.csv now contains per-query rows for all three systems
Re-running an existing system replaces its rows rather than duplicating them, so the CSV files always contain exactly one row per unique system name in aggregated.csv (and one row per system/query/measure combination in perquery.csv).
Missing Topics and/or Qrels¶
There is not always a one-to-one correspondance between the topic/query IDs (qids) that appear in
the provided topics and qrels. Qids that appear in topics but not qrels can be due to incomplete judgments,
such as in sparsely labeled datasets or shared tasks that choose to omit some topics (e.g., due to cost).
Qids that appear in qrels but no in topics can happen when running a subset of topics for testing purposes
(e.g., topics.head(5)).
The filter_by_qrels and filter_by_topics parameters control the behaviour of an experiment when topics and qrels
do not perfectly overlap. When filter_by_qrels=True, topics are filtered down to only the ones that have qids in the
qrels. Similarly, when filter_by_topics=True, qrels are filtered down to only the ones that have qids in the topics.
For example, consier topics that include qids A and B and qrels that include B and C. The results with
each combination of settings are:
|
|
Results consider |
Notes |
|---|---|---|---|
|
|
|
|
|
|
|
Acts as an intersection of the qids found in the qrels and topics. |
|
|
|
Acts as a union of the qids found in qrels and topics. |
|
|
|
|
Note that, following IR evaluation conventions, topics that have no relevance judgments (A in the above example)
do not contribute to relevance-based measures (e.g., map), but still contribute to efficiency measures (e.g., mrt).
As such, aggregate relevance-based measures will not change based on the value of filter_by_qrels. When perquery=True,
topics that have no relevance judgments (A) will give a value of NaN, indicating that they are not defined
and should not contribute to the average.
The defaults (filter_by_topics=True and filter_by_qrels=False) were chosen because they likely reflect the intent
of the user in most cases. In particular, it runs all topics requested and evaluates on only those topics. However, you
may want to change these settings in some circumstnaces. E.g.:
If you want to save time and avoid running topics that will not be evaluated, set
filter_by_qrels=True. This can be particularly helpful for large collections with many missing judgments, such as MS MARCO.If you want to evaluate across all topics from the qrels set
filter_by_topics=False.
Note that in all cases, if a requested topic that appears in the qrels returns no results, it will properly contribute a score of 0 for evaluation.
Available Evaluation Measures¶
All trec_eval evaluation measure are available. Often used measures, including the name that must be used, are:
Mean Average Precision (map).
Mean Reciprocal Rank (recip_rank).
Normalized Discounted Cumulative Gain (ndcg), or calculated at a given rank cutoff (e.g. ndcg_cut_5).
Number of queries (num_q) - not averaged.
Number of retrieved documents (num_ret) - not averaged.
Number of relevant documents (num_rel) - not averaged.
Number of relevant documents retrieved (num_rel_ret) - not averaged.
Interpolated recall precision curves (iprec_at_recall). This is family of measures, so requesting iprec_at_recall will output measurements for IPrec@0.00, IPrec@0.10, etc.
Precision at rank cutoff (e.g. P_5).
Recall (recall) will generate recall at different cutoffs, such as recall_5, etc.).
Mean response time (mrt) will report the average number of milliseconds to conduct a query (this is calculated by
pt.Experiment()directly, not pytrec_eval).trec_eval measure families such as official, set and all_trec will be expanded. These result in many measures being returned. For instance, asking for official results in the following (very wide) output reporting the usual default metrics of trec_eval:
name |
NumQ |
NumRet |
NumRel |
NumRet(rel=1) |
AP |
Rprec |
Bpref |
RR |
P@5 |
||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
0 |
TF_IDF |
93 |
91930 |
2083 |
20.8387 |
0.290905 |
0.301125 |
0.934214 |
0.699168 |
0.725414 |
0.640478 |
0.520824 |
0.406439 |
0.336222 |
0.267922 |
0.197803 |
0.151191 |
0.104208 |
0.0575086 |
0.0240411 |
0.473118 |
0.35914 |
0.304659 |
0.273118 |
0.236201 |
0.126344 |
0.0785484 |
0.0379785 |
0.0208387 |
1 |
BM25 |
93 |
91930 |
2083 |
20.828 |
0.296517 |
0.303662 |
0.934607 |
0.725665 |
0.751261 |
0.658588 |
0.523882 |
0.411899 |
0.345536 |
0.274788 |
0.207526 |
0.159466 |
0.105463 |
0.0579222 |
0.0238924 |
0.460215 |
0.352688 |
0.302509 |
0.269892 |
0.236918 |
0.126667 |
0.0779032 |
0.0379785 |
0.020828 |
See also a list of common TREC eval measures.
Evaluation Measures Objects¶
Using the ir_measures Python package, PyTerrier supports evaluation measure objects. These make it easier to express measure configurations such as rank cutoffs:
from pyterrier.measures import *
pt.Experiment(
[tfidf, bm25],
dataset.get_topics(),
dataset.get_qrels(),
eval_metrics=[AP, RR, nDCG@5],
)
NB: We have to use from pyterrier.measures import *, as from pt.measures import * wont work.
More specifically, lets consider the TREC Deep Learning track passage ranking task, which requires NDCG@10, NDCG@100 (using graded labels), as well as MRR@10 and MAP using binary labels (where relevant is grade 2 and above). The necessary incantation of pt.Experiment() looks like:
from pyterrier.measures import *
dataset = pt.get_dataset("trec-deep-learning-passages")
pt.Experiment(
[tfidf, bm25],
dataset.get_topics("test-2019"),
dataset.get_qrels("test-2019"),
eval_metrics=[RR(rel=2), nDCG@10, nDCG@100, AP(rel=2)],
)
The available evaluation measure objects are listed below.
- pyterrier.measures.P(**kwargs)¶
Basic measure for that computes the percentage of documents in the top cutoff results that are labeled as relevant. cutoff is a required parameter, and can be provided as P@cutoff.
Citation
Rijsbergen. Information Retrieval. 1979.
@book{DBLP:books/bu/Rijsbergen79, author = {C. J. van Rijsbergen}, title = {Information Retrieval}, publisher = {Butterworth}, year = {1979}, isbn = {0-408-70929-4}, timestamp = {Thu, 03 Jan 2002 11:51:10 +0100}, biburl = {https://dblp.org/rec/books/bu/Rijsbergen79.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
- pyterrier.measures.R(**kwargs)¶
Recall@k (R@k). The fraction of relevant documents for a query that have been retrieved by rank k.
NOTE: Some tasks define Recall@k as whether any relevant documents are found in the top k results. This software follows the TREC convention and refers to that measure as Success@k.
- pyterrier.measures.AP(**kwargs)¶
The [Mean] Average Precision ([M]AP). The average precision of a single query is the mean of the precision scores at each relevant item returned in a search results list.
AP is typically used for adhoc ranking tasks where getting as many relevant items as possible is. It is commonly referred to as MAP, by taking the mean of AP over the query set.
Citation
Harman. Evaluation Issues in Information Retrieval. Inf. Process. Manag. 1992. [link]
@article{DBLP:journals/ipm/Harman92, author = {Donna Harman}, title = {Evaluation Issues in Information Retrieval}, journal = {Inf. Process. Manag.}, volume = {28}, number = {4}, pages = {439--440}, year = {1992}, url = {https://doi.org/10.1016/0306-4573(92)90001-G}, doi = {10.1016/0306-4573(92)90001-G}, timestamp = {Fri, 21 Feb 2020 13:11:30 +0100}, biburl = {https://dblp.org/rec/journals/ipm/Harman92.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
- pyterrier.measures.RR(**kwargs)¶
The [Mean] Reciprocal Rank ([M]RR) is a precision-focused measure that scores based on the reciprocal of the rank of the highest-scoring relevance document. An optional cutoff can be provided to limit the depth explored. rel (default 1) controls which relevance level is considered relevant.
Citation
Kantor and Voorhees. The TREC-5 Confusion Track: Comparing Retrieval Methods for Scanned Text. Inf. Retr. 2000. [link]
@article{DBLP:journals/ir/KantorV00, author = {Paul B. Kantor and Ellen M. Voorhees}, title = {The {TREC-5} Confusion Track: Comparing Retrieval Methods for Scanned Text}, journal = {Inf. Retr.}, volume = {2}, number = {2/3}, pages = {165--176}, year = {2000}, url = {https://doi.org/10.1023/A:1009902609570}, doi = {10.1023/A:1009902609570}, timestamp = {Thu, 14 Oct 2021 09:13:06 +0200}, biburl = {https://dblp.org/rec/journals/ir/KantorV00.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
- pyterrier.measures.nDCG(**kwargs)¶
The normalized Discounted Cumulative Gain (nDCG). Uses graded labels - systems that put the highest graded documents at the top of the ranking. It is normalized wrt. the Ideal NDCG, i.e. documents ranked in descending order of graded label.
Citation
Järvelin and Kekäläinen. Cumulated gain-based evaluation of IR techniques. ACM Trans. Inf. Syst. 2002. [link]
@article{DBLP:journals/tois/JarvelinK02, author = {Kalervo J{\"{a}}rvelin and Jaana Kek{\"{a}}l{\"{a}}inen}, title = {Cumulated gain-based evaluation of {IR} techniques}, journal = {{ACM} Trans. Inf. Syst.}, volume = {20}, number = {4}, pages = {422--446}, year = {2002}, url = {http://doi.acm.org/10.1145/582415.582418}, doi = {10.1145/582415.582418}, timestamp = {Fri, 09 Jun 2017 11:03:19 +0200}, biburl = {https://dblp.org/rec/journals/tois/JarvelinK02.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
- pyterrier.measures.ERR(**kwargs)¶
The Expected Reciprocal Rank (ERR) is a precision-focused measure. In essence, an extension of reciprocal rank that encapsulates both graded relevance and a more realistic cascade-based user model of how users brwose a ranking.
- pyterrier.measures.Success(**kwargs)¶
1 if a document with at least rel relevance is found in the first cutoff documents, else 0.
NOTE: Some refer to this measure as Recall@k. This software follows the TREC convention, where Recall@k is defined as the proportion of known relevant documents retrieved in the top k results.
- pyterrier.measures.Judged(**kwargs)¶
Percentage of results in the top k (cutoff) results that have relevance judgments. Equivalent to P@k with a rel lower than any judgment.
- pyterrier.measures.NumQ(**kwargs)¶
The total number of queries.
- pyterrier.measures.NumRet(**kwargs)¶
The number of results returned. When rel is provided, counts the number of documents returned with at least that relevance score (inclusive).
- pyterrier.measures.NumRelRet(**kwargs)¶
The number of results returned. When rel is provided, counts the number of documents returned with at least that relevance score (inclusive).
- pyterrier.measures.NumRel(**kwargs)¶
The number of relevant documents the query has (independent of what the system retrieved).
- pyterrier.measures.Rprec(**kwargs)¶
The precision at R, where R is the number of relevant documents for a given query. Has the cute property that it is also the recall at R.
Citation
Buckley and Voorhees. Retrieval System Evaluation. 2005. [link]
- pyterrier.measures.Bpref(**kwargs)¶
Binary Preference (Bpref). This measure examines the relative ranks of judged relevant and non-relevant documents. Non-judged documents are not considered.
Citation
Buckley and Voorhees. Retrieval evaluation with incomplete information. SIGIR 2004. [link]
@inproceedings{DBLP:conf/sigir/BuckleyV04, author = {Chris Buckley and Ellen M. Voorhees}, editor = {Mark Sanderson and Kalervo J{\"{a}}rvelin and James Allan and Peter Bruza}, title = {Retrieval evaluation with incomplete information}, booktitle = {{SIGIR} 2004: Proceedings of the 27th Annual International {ACM} {SIGIR} Conference on Research and Development in Information Retrieval, Sheffield, UK, July 25-29, 2004}, pages = {25--32}, publisher = {{ACM}}, year = {2004}, url = {https://doi.org/10.1145/1008992.1009000}, doi = {10.1145/1008992.1009000}, timestamp = {Thu, 14 Oct 2021 10:27:19 +0200}, biburl = {https://dblp.org/rec/conf/sigir/BuckleyV04.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
- pyterrier.measures.infAP(**kwargs)¶
Inferred AP. AP implementation that accounts for pooled-but-unjudged documents by assuming that they are relevant at the same proportion as other judged documents. Essentially, skips documents that were pooled-but-not-judged, and assumes unjudged are non-relevant.
Pooled-but-unjudged indicated by a score of -1, by convention. Note that not all qrels use this convention.
Validation of Transformers¶
When formulating pipelines for a pt.Experiment(), its possible to formulate invalid pipelines, e.g. a transformer that does not produce the expected columns, or a transformer that does not accept the input columns of the previous transformer.
To mitigate this, pt.Experiment() will validate the transformers in the pipeline, and raise an error if the pipeline is invalid.
This validation is controlled by the validate= kwarg, which can take the following values:
- "warn" (default): If the pipeline is invalid, a warning is issued, but the experiment proceeds. Pipelines that do not validate will still run, but may produce unexpected results.
- "error": If the pipeline is invalid, an error is raised, and the experiment does not proceed. If a pipeline is not validated, the user is informed such that the experiment fails-fast.
- "ignore": No validation is performed, and the experiment proceeds. This is useful for pipelines that are known to be valid, but cannot be validated due to transformer objects that cannot be inspected to determing their input and output columns.
Validation uses pt.inspect.transformer_outputs() to determine the output columns of each transformer in the pipeline, and whether they match the expected input columns of the next transformer, and that the overall result of the pipeline has the expected columns for the evaluation measures requested.
Most transformers can be validated automatically, particularly if they respond correctly to an empty DataFrame input. Other transformers may require a transform_output method to be implemented, which returns the expected output columns of the transformer.
If a pipeline fails validation, the user is informed of the problem, and, if validate=”error” is set, the experiment does not proceed. On the other hand, if a pipeline cannot be validated (because a transformer cannot be inspected), a warning is issued, and the experiment proceeds.
Experiment Planning for Shared Computation¶
In many IR pipeline experiment settings, several pipelines share substantial computation. pt.Experiment supports experiment planning via the plan kwarg, which provides options to detect how shared computation is detected and reused.
Users can choose between two planning strategies:
plan="linear": Uses linear execution. This corresponds to computing each stage sequentially, and is the default behaviour.plan="tree": Uses tree execution, which can detect and reuse shared subsequences beyond the initial common prefix.
For a simple pair of pipelines, the tree excecution plan avoids repeated execution of the same initial retriever:
from pyterrier_t5 import MonoT5ReRanker, DuoT5ReRanker
bm25 = pt.terrier.Retriever.from_dataset('vaswani', 'terrier_stemmed_text', wmodel='BM25', num_results=100)
monoT5 = MonoT5ReRanker()
duoT5 = DuoT5ReRanker()
pt.Experiment(
[bm25, bm25 >> monoT5],
pt.get_dataset('vaswani').get_topics(),
pt.get_dataset('vaswani').get_qrels(),
eval_metrics=['map'],
plan='linear',
)
Without reuse, bm25 would be executed once per pipeline. Under plan="linear", the shared prefix is executed once and reused by downstream stages.
The benefit of plan="tree" is more pronounced when pipelines share deeper subsequences:
pt.Experiment(
[
bm25 % 100,
bm25 % 100 >> monoT5,
bm25 % 100 >> monoT5 % 10 >> duoT5,
bm25 % 100 >> monoT5 % 20 >> duoT5,
],
dataset.get_topics(),
dataset.get_qrels(),
[NDCG@10],
plan='tree',
)
In this example, both plans identify bm25 % 100 as a shared prefix. However, plan="tree" can additionally identify the shared monoT5 subsequence and reuse it across branches, reducing redundant computation relative to plan="linear". The following progress visualization illustrates the execution of the above experiment under plan="tree". Each transformer is represented as a node in the tree, with color indicating its execution status: red for not yet executed, yellow for currently executing, and green for completed. This visualisation is shown unless verbose=False is set.
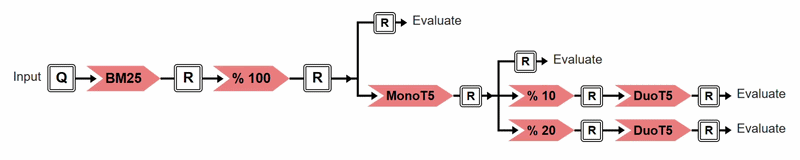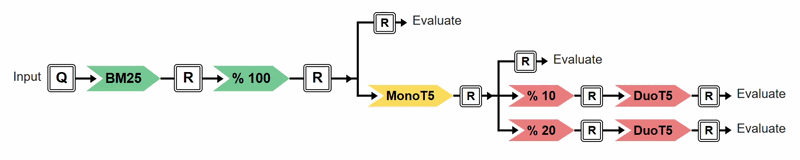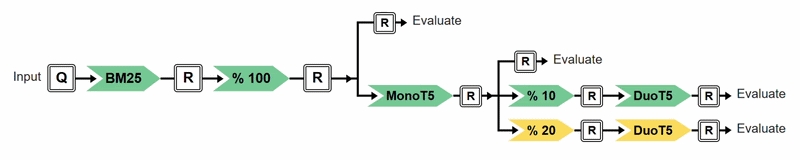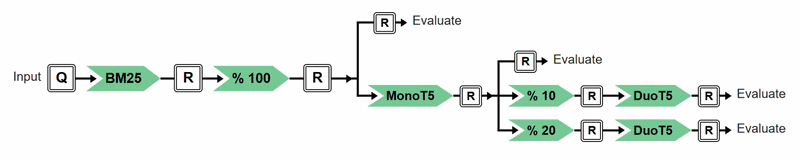
Progress visualisation of the execution of the above experiment under plan="tree".¶